
Problem statement
Nowadays, fast-growing Machine Learning technologies allow us to solve an increasing number of real-life problems. Routine operations in such cases can be reduced by creating a system that allows algorithm developers to focus on their tasks instead of on supplying execution environments. We created such a platform and tested it on one of the most interesting problems — market values prediction. To get things more interesting, we used Bitcoin price changes as a data source.
If you bought one Bitcoin in December 2012 as a Christmas present, your $13 would be worth around $8,000 today.
You can hear many similar stories from people the world over. Nobody knows exactly what the prices for Bitcoin or any other cryptocurrency will be in the next hour, day, week, month, etc., but there is a possibility to forecast it based on news.
The news is usually a driving force of the markets, their lack or low level of importance could lead to the fact that the market can simply stand still.
This article is aimed to show how to build a Machine Learning platform using Big Data technologies that could help to forecast the value of a particular market based on news from around the world.
Data Sources
To enable us to do any analysis, we have to get access to data sets required for this task. We need at least 2 data sources: one for Bitcoin market values and one with information about Bitcoin-related mass media mentions.
Finding data sources for Bitcoin market values is a relatively simple. There are various options around, and we just need to choose one of them. Our choice isn’t really important here, so let’s not get too focused on this. We used Yahoo Finance, because it’s free, reliable and has multiple program libraries to work with.
Working with information from mass media is far more complicated. To achieve an objective picture we should gather news from numerous sources. After putting together a list of such news origins, we will certainly face a series of difficulties, such as different languages, data source stability, information storage. But in fact, all of these issues aren’t a big deal compared to the main challenge — estimation of a news effect by a set of parameters. This challenge is a part of computer science and artificial intelligence called Natural Language Processing. Nowadays, it’s a fast-developing field with an emphasis on Machine Learning.
Fortunately, GDELT project can help us with the news data source. GDELT is a Global Database of Events, Language, and Tone; supported by Google Jigsaw. Quote from the official site: “the GDELT project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organizations, themes, sources, emotions, counts, quotes, images and events driving our global society every second of every day”. This is exactly what we are looking for. Now we have everything that we need to get started.
Solution Design
With the data sources listed above, we can discuss our solution design. At first, let’s create a list of features that we want to see in our solution, and explain how we are supporting those features:
- Easy to run algorithm execution. During the search for an optimal algorithm, developers should be able to go through multiple iterations with easy access to data, source code and previous attempts without the necessity of taking care of anything except the algorithm itself. This is supported by an application template that encapsulates all of the logic for data access and executions. It’s called ml-template.
- Effective data processing. For the purpose of working with large amounts of data efficiently, we will be using Apache Spark which has powerful tools for Machine Learning algorithms implementations via Spark ML.
- Ability to add new data source can be achieved by a separate microservice for data management. Data Service will be responsible for downloading news (GDELT data) with related stock market data (Yahoo Finance) and saving them to the database.
- Ability to use different programming languages for algorithms development is provided by Executor Service — a microservice for downloading and compiling algorithm sources, model training, running algorithms on the Spark cluster. It doesn’t depend on a specific technology and can run everything that can be executed from the command line.
- Results comparison. There’s an another microservice called Results Evaluation Service designed for receiving results from the ml-template and calculating a score for each algorithm execution result.
- Web-interface for executions management. The user interface will be communicating with our microservices using WebSocket.
And the finishing touch — the name Midas was chosen for the project. The mythical king Midas turned things into gold, and our system is designed to turn the data into “gold”.
Infrastructure for the Solution
To get a complete and usable product we should determine the infrastructure to use. Since we have need of multiple nodes use (microservices, data storages, Spark nodes) in solution, it would be reasonable to use Dockerimages instead of real or virtual machines for each node.
As a container management platform, we will be using Rancher. This platform includes RancherOS — simplified Linux distribution specially prepared for the container management. For container orchestration purposes it uses Cattle by default, but also allows to use other tools like Docker Swarm or Kubernetes.
For the Apache Spark cluster management, we will be using Apache Mesos. It’s a powerful resource sharing tool designed especially for cluster-based program solutions like Spark. You can read more about benefits of our choice in this article from the University of California.
Also, we will need some program solution for logs handling. Pipeline for this will consist of 3 tools: FluentD for logs collection; ElasticSearch for storage and searching; Kibana for visualization.
And the last component of our infrastructure is a continuous delivery tool. For this we use one of the most popular instruments — Jenkins.

Infrastructure diagram
Workflow

Standard workflow is presented on the picture above. The numbers on the diagram have the following meaning:
- The user accesses Frontend (web application, aka Midas Eyes) to obtain information about existing models and previous executions. Also, the user can create and train the new model or apply an existing one as a new input data via the UI.
- Information about executions and models is requested from Executor Service by Frontend via WebSocket.
- Metadata of models and executions is stored in the PostgreSQL database.
- Results and their estimations are requested from Result Evaluation Service by Frontend via WebSocket.
- Results and estimations are stored in the PostgreSQL database.
- When “train” execution has been started, Executor Service downloads sources from GitLab. For the “apply” execution they are already stored and can be run immediately. Then Executor Service runs the ml-template extended by a developer with some algorithm.
- Before starting a job on the Spark cluster, ml-template checks an existence of the input data, specified by the user, in Data Service via REST API.
- If data, required by the execution, is missing, Data Service downloads it from external sources — in our case, GDELT and Yahoo.
- Data Service stores downloaded data in the Mongo database.
- When data is ready, ml-template submits the task to the Spark cluster.
- During the execution Spark requests necessary data from the Mongo database.
- When execution is finished, results are submitted to Result Evaluation Service. This service makes necessary estimates including comparison with the ground truth (“label” in terms of Spark).
Also, a few words about the technological stack of microservices. Data, Execution and Result Evaluation services are powered by Java, Spring Boot, Hibernate and Gradle. The ml-template is written using Scala, but can be created also on Python, R or Java. Frontend is based on React.js and Bootstrap.
Examples of algorithms application
As a warm up let’s try Linear Regression algorithm. Our initial assumption is the correlation between Bitcoin price and derivatives from the average tone of news. The average tone is the measure of mentions of the event. It ranges between -100 and +100, where 0 is the neutral value. This parameter is a large array of values, usually about thousands of numbers. But it can be turned into several weights according to the distribution by amounts and positive/negative values. After simple calculation, we get the mean tone and total amounts.
The hypothesis about linear dependency between news and market data is pretty naive, but it’s a good starting point. Using it we can check that everything is working as planned. As expected, results at this point aren’t encouraging, as seen in the graph below.
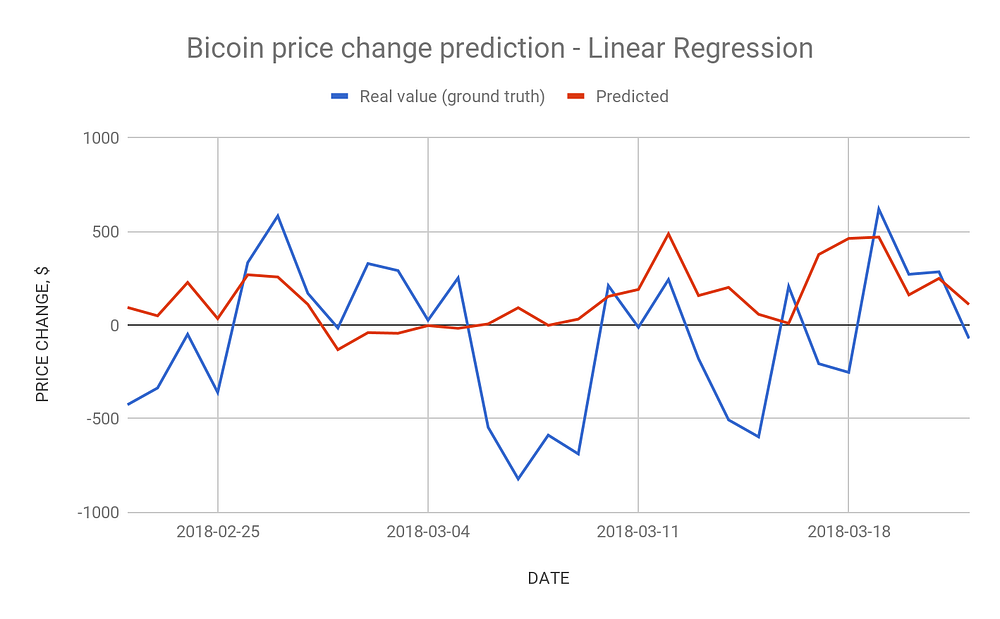
This is just one of many attempts, none of them resulted in mean deviations better than hundreds of dollars. More relevant algorithms, such as gradient-boosted-tree regression, also showed unreliable results.
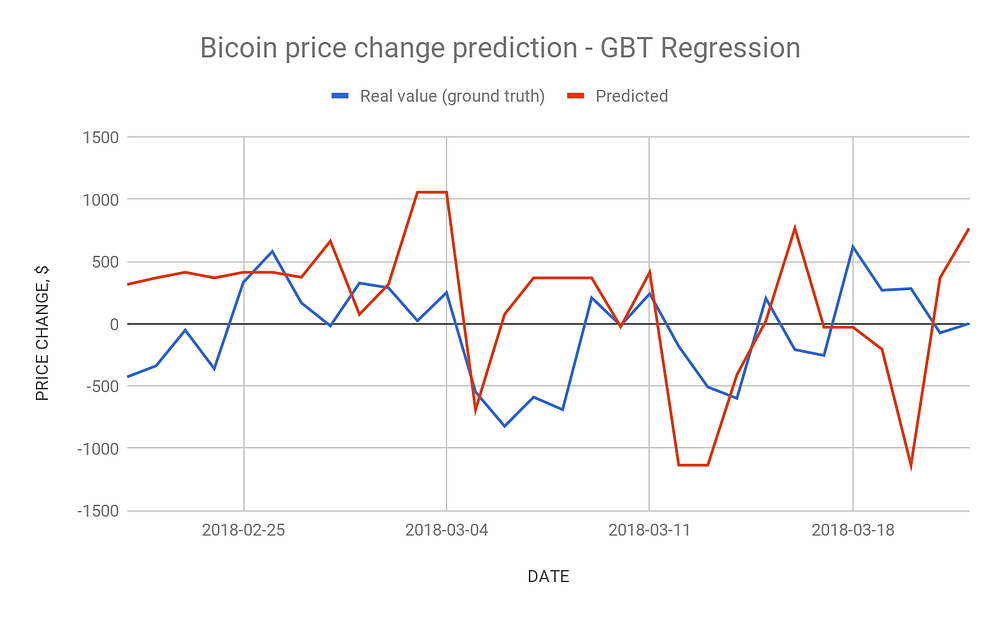
This means that we need to improve current algorithms using techniques such as cross-validation or try new ones. For example, usage of Deep Learning (especially, Deep Neural Networks) with Apache Spark is one of interesting approaches. Also, we possibly need to change our set of input parameters. In this way, we have a wide range of possible directions to improve.
Conclusion
Our work on this project is still in progress. Developers are working on their versions of algorithms, trying to achieve better results. During the exploitation of the system a number of ideas appeared in our minds, and we’re trying to get them alive as well.
Currency prediction is not the only one application area possible. For example, It will be easy to get it working on market stocks as well. Such stocks have more news parameters to operate with because they are linked to specific countries or companies and depend on the events related to those countries and companies.
Technologies that we have used during this project are open source. In this article we have shown you how to easily build complex Machine Learning solution instead of using existing solutions on the market. We hope that our experience will inspire you to do your own interesting projects.
About us
We at Akvelon Inc love cutting edge technologies such as blockchain, big data, machine learning, artificial intelligence, computer vision and many others. This is one of many projects developed in our Office Strategy Labs.
If you’re interested in contributing to a project, or have an interesting idea — contact us. Or if you would like to work with our strong Akvelon team — please see our open positions.
Written in collaboration with Artur Zaripov

Nail Shakirov is a Project Manager at Akvelon. He has a solid software development background and experience in all software development stages: technical design, implementation, testing, and operation.
Article written by Akvelon Project Manager Nail Shakirov was originally published in Medium and then also published on Towards Data Science.